こんにちはAIチームの友松です。
本記事では、ElasticsearchでSudachiとベクトル検索を組み合わせて使う方法について2回に分けて解説を行いたいと思います。今回はSudachi導入までを行いたいと思います。
Elasticsearchにおける文書検索
analyzerについて
analyzerはcharacter filter, tokenizer, token filterの3つで構成されています。analyzerは文書が与えられるとcharacter filter → tokenize → token_filterの順で解析を行います。
character filter
character filterはtokenizerに渡す前の前処理として文字ベースのfilterを行います。組み込みのcharacter filterは現時点で3つ存在します。
- mapping-char-filter
- 文字列の置換を行います。
- pattern-replace-char-filter
- 文字列の正規表現による置換を行います
- html-Strip-char-filter
- HTMLタグの除去を行い、HTMLエレメントをデコードされた値への変換を行います
tokenizer
tokenizerでは、char filterで処理された文字列を受け取ってtokenへの分割を行います。
組み込みのtokenizerが数多く提供されています。
例えば This is a pen.のように英語の文章は空白で分割を行えば単語への分割が行えます。これらを分割したい場合にはwhite space tokenizerが利用できます。white space tokenizerを使用すると以下のような変換ができます。
Input: This is a pen.
Output: [This, is, a, pen]
token filter
token filterでは、tokenizerで分割された各tokenに対してトークンの変更(小文字化など)、トークンの削除(ストップワードの削除など)、またはトークンの追加(類義語など)を行うことができます。
日本語検索用のプラグイン
入力文章が英語の場合は単語を区切る際、空白で区切れば良かったのですが、日本語を単語で区切る場合は形態素解析を行う必要があります。日本語の形態素解析を行うためにはElasticsearchのプラグインを導入する必要があります。主にanalysis-kuromojiとanalysis-sudachiがありますが、本記事ではanalysis-sudachiについて紹介したいと思います。
analysis-sudachi
analysis-sudachiはワークス徳島人工知能NLP研究所によって作られた日本語検索用のプラグインです。こちらのプラグインには形態素解析器Sudachiによるtokenizerと5種類のtoken-filterが含まれています。
tokenizer
analysis-sudachiのtokenizerはsudachi-tokenizerと呼びます。
Sudachiの特徴として複数の分割モードを提供している点です。
- AはUniDic短単位相当
- Cは固有表現相当
- BはA, Cの中間的な単位
検索用途であれば A と C を併用することで、再現率と適合率を向上させる ことができます。sudachi-tokenizerでAとCを適用する場合はmodeを'search'に指定します。
(公式より引用)
A:医薬/品/安全/管理/責任/者
B:医薬品/安全/管理/責任者
C:医薬品安全管理責任者
A:消費/者/安全/調査/委員/会
B:消費者/安全/調査/委員会
C:消費者安全調査委員会
A:さっぽろ/テレビ/塔
B:さっぽろ/テレビ塔
C:さっぽろテレビ塔
A:カンヌ/国際/映画/祭
B:カンヌ/国際/映画祭
C:カンヌ国際映画祭token filter
analysis-sudachiには5種類のtoken filterがあります。
- sudachi_part_of_speech
- 指定した品詞のtokenを除外する
- sudachi_ja_stop
- 指定したストップワードと一致するtokenを除外する
- sudachi_base_form
- 各tokenをSudachiBaseFormAttributeに変換する
- 例) 飲み → 飲む
- sudachi_normalizedform
- 各tokenをSudachiNormalizedFormAttributeに変換する
- 例) 呑み → 飲む
- sudachi_readingform
- 各tokenをカタカナおよびローマ字の読みに変換する
- 例) 寿司 → スシ or sushi
analysis-sudachiを用いた文書検索環境の構築
analysis-sudachiを搭載したElasticsearchのディレクトリ構成は以下のようになっています。
.
├── docker-compose.yml
├── es
│ ├── Dockerfile
│ ├── analysis-sudachi-elasticsearch7.3-1.3.1.zip
│ ├── sudachi.json
│ └── system_full.dic
└── index.jsonanalysis-sudachi-elasticsearch7.3-1.3.1.zip
こちらのファイルはElasticsearchのバージョンと対応しているものを使用しないと動作しません。Elasticsearchのバージョンと照らし合わせてこちらからダウンロードしてください
https://github.com/WorksApplications/elasticsearch-sudachi/releases
system_full.dic
system_full.dicはSudachiが形態素解析を行う際に利用する辞書です。
辞書の種類は[small, core, full]の3種類があり用途に応じた辞書を用いてください。辞書は以下のサイトからダウンロードできます
https://github.com/WorksApplications/SudachiDict
sudachi.json
こちらのファイルはSudachiの設定ファイルです。基本的にはデフォルトの値を使用しています。今回systemDictはsystem_full.dictを利用しているためこちらに変更しています。
https://github.com/WorksApplications/Sudachi/blob/develop/src/main/resources/sudachi.json
{
"systemDict" : "system_full.dic",
"inputTextPlugin" : [
{ "class" : "com.worksap.nlp.sudachi.DefaultInputTextPlugin" },
{ "class" : "com.worksap.nlp.sudachi.ProlongedSoundMarkInputTextPlugin",
"prolongedSoundMarks": ["ー", "-", "⁓", "〜", "〰"],
"replacementSymbol": "ー"}
],
"oovProviderPlugin" : [
{ "class" : "com.worksap.nlp.sudachi.MeCabOovProviderPlugin" },
{ "class" : "com.worksap.nlp.sudachi.SimpleOovProviderPlugin",
"oovPOS" : [ "補助記号", "一般", "*", "*", "*", "*" ],
"leftId" : 5968,
"rightId" : 5968,
"cost" : 3857 }
],
"pathRewritePlugin" : [
{ "class" : "com.worksap.nlp.sudachi.JoinNumericPlugin",
"joinKanjiNumeric" : true },
{ "class" : "com.worksap.nlp.sudachi.JoinKatakanaOovPlugin",
"oovPOS" : [ "名詞", "普通名詞", "一般", "*", "*", "*" ],
"minLength" : 3
}
]
}Dockerfile
FROM docker.elastic.co/elasticsearch/elasticsearch:7.3.2
COPY analysis-sudachi-elasticsearch7.3-1.3.1.zip /usr/share/elasticsearch/
RUN elasticsearch-plugin install file:///usr/share/elasticsearch/analysis-sudachi-elasticsearch7.3-1.3.1.zip
COPY sudachi.json /usr/share/elasticsearch/plugins/analysis-sudachi/
COPY system_full.dic /usr/share/elasticsearch/plugins/analysis-sudachi/
docker-compose.yml
version: '3'
services:
elasticsearch:
build: es
ports:
- 9200:9200
environment:
- discovery.type=single-node
- cluster.name=docker-cluster
- bootstrap.memory_lock=true
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
expose:
- 9300
ulimits:
nofile:
soft: 65536
hard: 65536ここまで準備できたら、実際にDockerを起動してElasticsearchを動かします。docker-compose.ymlがあるディレクトリで以下を実行します。
$ docker-compose upしばらく待つと、Elasticsearchが起動します。これでanalysis-sudachiを用いた文書検索を行うための環境構築は完了です。
indexの登録
Elasticsearchではテーブルに相当するindexと呼ばれるものがあります。
今回はsudachi_analyzerを定義しanalyzerのテストを行います。
{
"settings": {
"index": {
"analysis": {
"tokenizer": {
"sudachi_tokenizer": {
"type": "sudachi_tokenizer",
"mode": "search",
"discard_punctuation": true,
"resources_path": "/usr/share/elasticsearch/plugins/analysis-sudachi/",
"settings_path": "/usr/share/elasticsearch/plugins/analysis-sudachi/sudachi.json"
}
},
"analyzer": {
"sudachi_analyzer": {
"tokenizer": "sudachi_tokenizer",
"type": "custom",
"char_filter": [],
"filter": [
"sudachi_part_of_speech",
"sudachi_ja_stop",
"sudachi_baseform"
]
}
}
}
}
}
}tokenizerにsudachi_tokenizer, token_filterとしてsudachi_part_of_speech, sudachi_ja_stop, sudachi_baseformを指定したsudachi_analyzerを定義します。こちらの挙動をpythonのelasticsearch-clientを用いて確認します。
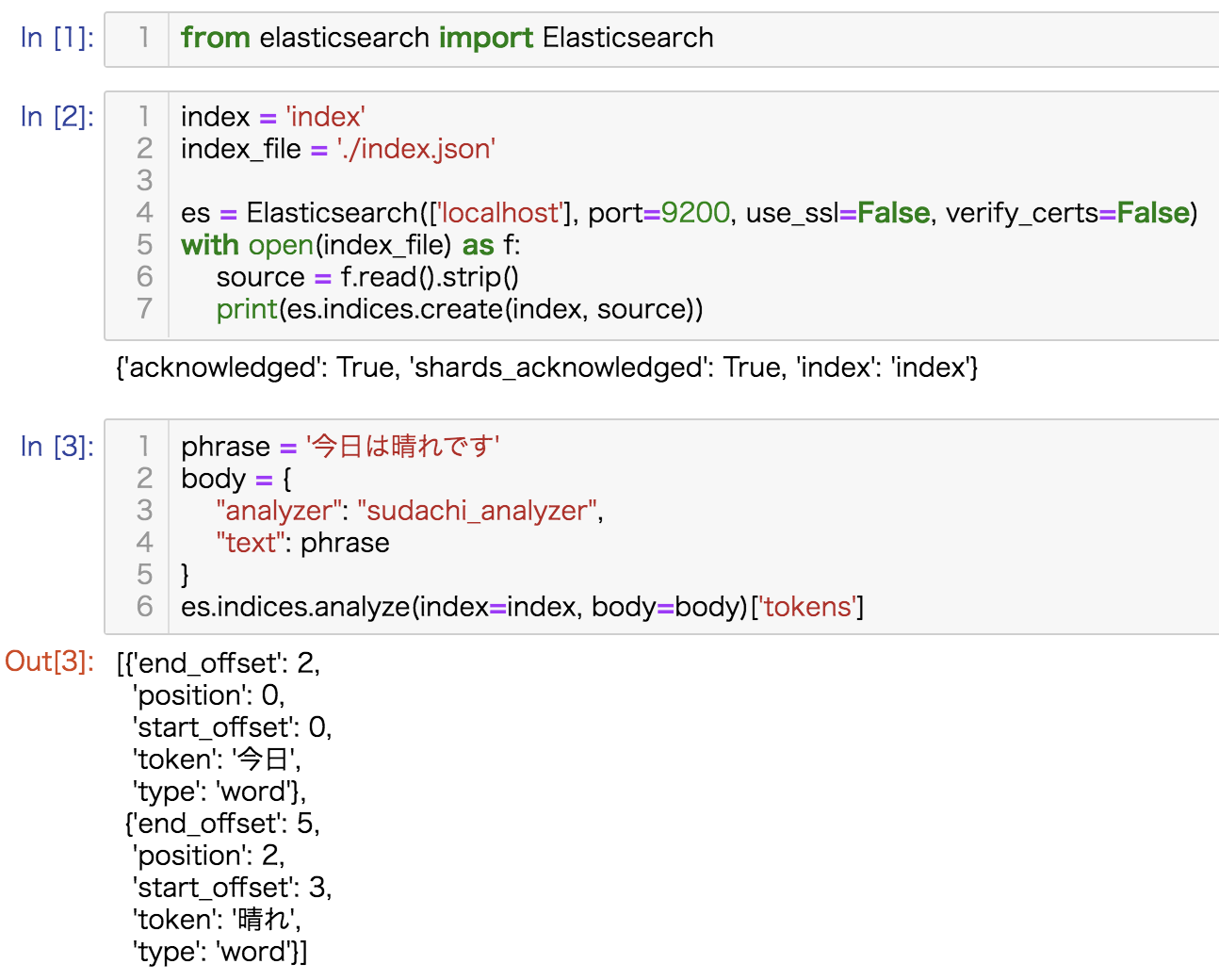
from elasticsearch import Elasticsearch
index = 'index'
index_file = './index.json'
es = Elasticsearch(['localhost'], port=9200, use_ssl=False, verify_certs=False)
with open(index_file) as f:
source = f.read().strip()
print(es.indices.create(index, source))
phrase = '今日は晴れです'
body = {
"analyzer": "sudachi_analyzer",
"text": phrase
}
es.indices.analyze(index=index, body=body)['tokens']今回はelasticsearchにanalysis_sudachiを組み込み、挙動を確認するところまで書きました。次回はベクトル検索も組み込みこれら両方を加味したスコアによって文書検索を行います。
参考
https://qiita.com/sorami/items/99604ef105f13d2d472b
https://github.com/WorksApplications/elasticsearch-sudachi




