こんにちは、AI Shiftの杉山です。
今回は個人情報が含まれた文章に対してFlairを用いることで、どれくらい個人情報を固有表現として抽出することができるのかを検証します。
背景
(NDAを結んだ上での)データの第三者提供時やDBに個人情報を残したくない顧客側の要望など、個人情報をマスキングする必要があるシーンは多くあると思います。
また、こちらの記事ではフランスでの判例公開時における個人情報マスキングの必要性が述べられています。
弊社が提供しているAIメッセンジャーというAIチャットボットサービスでも、お客様の本人確認などを行うために個人情報を入力していただくケースがありますので、そのようなデータの取り扱いに際して個人情報を抽出・削除したいというニーズを抱えています。
そこで、最終的には自動化したい考え現時点の機械学習の技術でどれくらいの制度が出るのか検証してみようと思います。
Flairとは
ここで、今回使用するFlairについて簡単に説明します。
FlairはZalando Researchによって開発されているNLPフレームワークで、独自のFlair Embeddingを用いることで固有表現抽出に強みを持ち、提案当時には多くの固有表現抽出タスクでSOTAを獲得しました。
最新の手法を手軽に実行できるのが特徴で、BERT族などのモデルも宣言的に実装することができます。(バックエンドはHugging Face/transformers)
予備実験で行った日本語の固有表現抽出においても高精度であったため今回はこちらを採用することにしました。
なお、インストールや実装面ではこちらの記事が大変参考になりました。
準備
Flairはあくまでも固有表現抽出の実装を提供するフレームワークなので、個人情報を固有表現として扱うにはそのための学習データを作成する必要があります。
そこで、今回はAIメッセンジャーの対話データに対してアノテーションを行い、データを作成しました。
なお、アノテーションにはTIS様からOSSで出されているdoccanoを用いました。(使いやすいUIで最高です!)
今回対象とした対話データを確認したところ、個人情報として以下の8項目が含まれていましたので、それぞれに対してIREXのIOB2タグ形式でアノテーションを行いました。
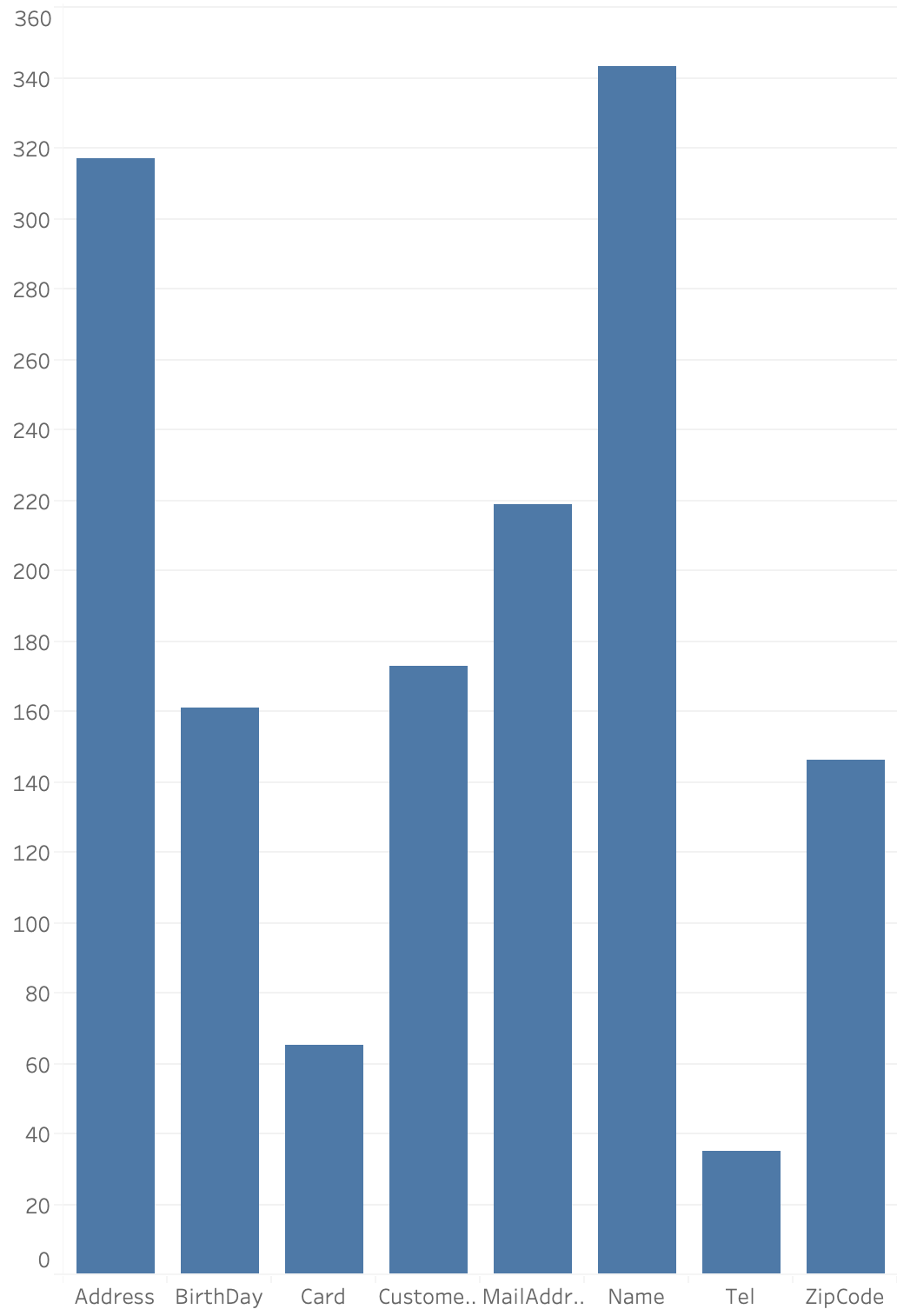
(かなり少ないですが)140の対話データにアノテーションを行ったところ、各タグの頻度分布は以下のようになりました。
今回対象とした対話データを確認したところ、個人情報として以下の8項目が含まれていましたので、それぞれに対してIREXのIOB2タグ形式でアノテーションを行いました。
| 個人情報 | タグ |
|---|---|
| 名前 | <Name> |
| 郵便番号 | <ZipCode> |
| 電話番号 | <Tel> |
| 住所 | <Address> |
| 生年月日 | <Birthday> |
| カード番号 | <Card> |
| メールアドレス | <MailAddress> |
| 会員番号 | <CustomerID> |
(かなり少ないですが)140の対話データにアノテーションを行ったところ、各タグの頻度分布は以下のようになりました
実装
実装はこちらの記事の通りなのですが、一応記載しておきます。
from flair.datasets import ColumnCorpus
from flair.embeddings import StackedEmbeddings, FlairEmbeddings
from flair.data import Sentence
from flair.models import SequenceTagger
from flair.trainers import ModelTrainer
columns = {0: 'text', 1: 'ner'}
data_folder = './resources/data/'
corpus = ColumnCorpus(data_folder, columns,
train_file='NER-train.txt')
tag_type = 'ner'
tag_dictionary = corpus.make_tag_dictionary(tag_type=tag_type)
embedding_types = [
FlairEmbeddings('ja-forward'),
FlairEmbeddings('ja-backward'),
]
embeddings = StackedEmbeddings(embeddings=embedding_types)
tagger = SequenceTagger(hidden_size=256,
embeddings=embeddings,
tag_dictionary=tag_dictionary,
tag_type=tag_type,
use_crf=True)
trainer = ModelTrainer(tagger, corpus)
trainer.train('./resources/taggers/example-ner',
learning_rate=0.1,
mini_batch_size=16,
max_epochs=100)実験
学習に際し、140件のデータをtrain:114, dev:12, test:14のように分割して検証を行いました。
パラメータは上記の通り
learning_rate: "0.1"
mini_batch_size: "16"
max_epochs: "100"で行いましたが、今回は63epoch目でearly_stopppingが行われ、手元のMac(no GPU)で15時間ほどで終わりました。
testデータでの結果は以下の通りです。
なお、固有表現抽出の評価にはB-やI-まで見る/見ない、や認識領域の完全一致/分割単位など様々な方法がありますが、Flairのコードを確認したところB-などを除くタグ+領域の完全一致で評価しているようです。
MICRO_AVG: acc 0.3333 - f1-score 0.5
MACRO_AVG: acc 0.2783 - f1-score 0.4036166666666667
Address tp: 20 - fp: 10 - fn: 12 - tn: 20 - precision: 0.6667 - recall: 0.6250 - accuracy: 0.4762 - f1-score: 0.6452
BirthDay tp: 6 - fp: 10 - fn: 10 - tn: 6 - precision: 0.3750 - recall: 0.3750 - accuracy: 0.2308 - f1-score: 0.3750
Card tp: 3 - fp: 5 - fn: 5 - tn: 3 - precision: 0.3750 - recall: 0.3750 - accuracy: 0.2308 - f1-score: 0.3750
CustomerID tp: 12 - fp: 4 - fn: 8 - tn: 12 - precision: 0.7500 - recall: 0.6000 - accuracy: 0.5000 - f1-score: 0.6667
MailAddress tp: 9 - fp: 15 - fn: 15 - tn: 9 - precision: 0.3750 - recall: 0.3750 - accuracy: 0.2308 - f1-score: 0.3750
Name tp: 16 - fp: 14 - fn: 20 - tn: 16 - precision: 0.5333 - recall: 0.4444 - accuracy: 0.3200 - f1-score: 0.4848
Tel tp: 0 - fp: 0 - fn: 4 - tn: 0 - precision: 0.0000 - recall: 0.0000 - accuracy: 0.0000 - f1-score: 0.0000
ZipCode tp: 4 - fp: 10 - fn: 14 - tn: 4 - precision: 0.2857 - recall: 0.2222 - accuracy: 0.1429 - f1-score: 0.2500MICRO_AVGのf1-scoreで0.5とそこそこ良い結果が出ていますが、個人情報のマスキング用途にそのまま用いるには頼りない数値となりました。
また、簡単そうなTelのtpが0になってしまったのですが、これはZipCodeが似た系列(TelはXXX-XXXX-XXX、ZipCodeはXXX-XXXX)を持つためそちらに寄ってしまったと考えられます。(実際ZipCodeのfpが高い)
実際のデータを使っているため適用例をお見せすることはできないのですが、一例として以下の例文に対して予測を行ってみたいと思います。
AI Shiftの杉山です。会社の住所は〒150-6122 東京都渋谷区渋谷渋谷スクランブルスクエアで、2019/12/18生まれです。
モデルの適用時には、文章ではなく学習時と同じ分割のスペース区切りで渡す必要があります。今回はMeCab+neologdで分割して学習したため、入力をそのように整形して予測します。
import MeCab
tagger = MeCab.Tagger("-d /usr/local/lib/mecab/dic/mecab-ipadic-neologd")
def separate(text):
morph_list = [t for t in tagger.parse(text).split('\n') if t not in ["", "EOS"]]
return ' '.join([t.split("\t")[0] for t in morph_list])
text = 'AI Shiftの杉山です。会社の住所は〒150-6122 東京都渋谷区渋谷渋谷スクランブルスクエアで、2019/12/18生まれです。'
sentence = Sentence(separate(text))
result = model.predict(sentence)
print(sentence.to_tagged_string())適用結果はこのようになりました。(スクランブルスクエアはまだneologdに登録されていないようです;;)
AI Shift の 杉山 です 。 会社 の 住所 は 〒 150 <I-ZipCode> - <I-ZipCode> 6122 <I-ZipCode> 東京都渋谷区渋谷 <B-Address> 渋谷 <I-Address> スクランブル <I-Address> スクエア <I-Address> で <I-Address> 、 <I-Address> 2019 <I-BirthDay> / <I-BirthDay> 12 <I-BirthDay> / <I-BirthDay> 18 <I-BirthDay> 生まれ です 。<B-Name>になるべき苗字が認識できていないのと、「で」と「、」がそれぞれ<I-Address>になってしまっていますが、それ以外は目的どおりに抽出することができています。
終わりに
本記事では、Flairによる固有表現抽出を用いて個人情報の抽出を行いました。
結果としてはまだまだ頼りない部分があるものの、前処理的に行って人のサポートとしてサジェストするくらいには使える可能性がありそうです。
ただ、電話番号やメールアドレスのような個人情報は、正規表現を用いたルールベースで機械的に抽出することができるので、ルールベースと固有表現抽出を組み合わせることでどれだけの精度になるか検証していきたいと思います。
また、今後はtestデータに現れる固有表現が既知/未知の場合に分けての精度検証や、BERTなどの言語モデルをfine-tuningして固有表現抽出する実験を行いたいと考えています。
このように、AI Shiftでは実際のサービスで使われている生きたテキストデータで最新の手法を試すことができます。こういった環境は非常に刺激的でやりがいがありますので、興味のある方は気軽にお声がけください!
参考文献
- https://github.com/zalandoresearch/flair
- http://nlpprogress.com/english/named_entity_recognition.html
- https://github.com/doccano/doccano
- https://hironsan.hatenablog.com/entry/implementing-contextual-string-embeddings-for-named-entity-recognition
- http://www.davidsbatista.net/blog/2018/05/09/Named_Entity_Evaluation/




