こんにちわ
AIチームの戸田です
前回、 前々回に引き続き、学習済みのBERTのモデルを使ってTOEICの問題を解いてみようと思います。
今回はいよいよ最難関と思われるPart7です。
Part7は長文読解問題で、英語の長文を読んで内容に関する設問に答えます。
前々回の最後にも話しましたが問題としてはSQuADに近いと思うので、SQuADでfine-tuningされたモデルを使おうと思います。
今回も問題はIIBC公式のサンプル問題を使用させていただきます。
SQuADについて
SQuAD とは The Stanford Question Answering Dataset の略で、スタンフォード大学が作った質問応答データセットです。
1つの問題がwikipediaの記事からきたテキスト、その内容に対する質問文、テキストの中にある質問に対する回答のセットで構成されています。
例えば以下のような形になります
テキスト
Beyoncé Giselle Knowles-Carter (/biːˈjɒnseɪ/ bee-YON-say) (born September 4, 1981) is an American singer, songwriter, record producer and actress. Born and raised in Houston, Texas, she performed in various singing and dancing competitions as a child, and rose to fame in the late 1990s as lead singer of R&B girl-group Destiny's Child. Managed by her father, Mathew Knowles, the group became one of the world's best-selling girl groups of all time. Their hiatus saw the release of Beyoncé's debut album, Dangerously in Love (2003), which established her as a solo artist worldwide, earned five Grammy Awards and featured the Billboard Hot 100 number-one singles "Crazy in Love" and "Baby Boy".
質問文
When did Beyonce start becoming popular?
回答
in the late 1990s (開始位置269文字目)
アメリカのシンガーソングライター、ビヨンセさんの記事ですね。
有名になったのはいつからか、という質問に対して1990年後半という回答になります。
SQuADにはver 2.0から答えられない問題is_impossibleも考慮する必要がありますが今回は割愛させていただきます。
BERT学習済みモデルの読み込み
ここから実装に入ります。
毎度お世話になっているhuggingfaceのtransformersを利用します。
import torch
from transformers import BertTokenizer, BertForPreTraining
tokenizer = BertTokenizer.from_pretrained('bert-large-cased-whole-word-masking-finetuned-squad')
model = BertForQuestionAnswering.from_pretrained('bert-large-cased-whole-word-masking-finetuned-squad')
以前まではbaseモデルを利用していましたが、今回はSQuADでfine-tuningされたモデルを利用します。
問題定義
textに問題の文章、question1, 2に質問、candidate1, 2にそれぞれの回答候補をリストで定義します
text = """
Used Car For Sale. Six-year-old Carlisle Custom.
Only one owner.
Low mileage.
Car used to commute short distances to town.
Brakes and tires replaced six months ago.
Struts replaced two weeks ago.
Air conditioning works well, but heater takes a while to warm up.
Brand new spare tire included.
Priced to sell.
Owner going overseas at the end of this month and must sell the car.
Call Firoozeh Ghorbani at (848) 555-0132.
"""
question1 = "What is suggested about the car?"
question2 = "According to the advertisement, why is Ms. Ghorbani selling her car?"
candidate1 = [
"It was recently repaired.",
"It has had more than one owner.",
"It is very fuel efficient.",
"It has been on sale for six months.",
]
candidate2 = [
"She cannot repair the car’s temperature control.",
"She finds it difficult to maintain.",
"She would like to have a newer model.",
"She is leaving for another country.",
]
回答方法
SQuADで学習したモデルはテキストと質問文を入力して、回答のテキスト内での位置を出力します。
Part7でも同様にテキストと質問文を入力して、出力された回答位置から回答文を抽出し、Part6のときと同じように、ベクトル化したときに最もcos類似度が近い候補を回答とすることとします。
問題文章をTokenIDのリストに変換する
今回は質問文とテキストを特殊トークン[SEP]で区切ってトークン化します。
tokens = ["[CLS]"] + tokenizer.tokenize(question1) + ["[SEP]"] + tokenizer.tokenize(text) + ["[SEP]"]
input_ids = tokenizer.convert_tokens_to_ids(tokens)TokenIDのタイプを設定
テキストと質問文の範囲を指定するtoken_type_idsを定義します。[SEP]トークンのIDが102なので、それ以降を1にしています。
token_type_ids = [0 if i <= input_ids.index(102) else 1 for i in range(len(input_ids))]BERTによる予測
BERTのモデルで予測をします。
出力は回答がトークンのどの範囲にあるのかの開始位置と終了位置のスコアです。
with torch.no_grad():
start_scores, end_scores = model(torch.tensor([input_ids]), token_type_ids=torch.tensor([token_type_ids]))回答を確認
出力されたトークンで最もスコアの高い位置のテキストを回答として抽出します。
all_tokens = tokenizer.convert_ids_to_tokens(input_ids)
answer_token = all_tokens[torch.argmax(start_scores):torch.argmax(end_scores)+1]
print("answer token:", " ".join(answer_token))
ans = ""
for a in answer_token:
if "#" in a:
ans += a.replace("#", "")
else:
ans += " " + a
print("extract answer:", ans)
# answer token: Low mile ##age . Car used to com ##mu ##te short distances to town
# extract answer: Low mile age. Car used to commute short distances to town
車について述べられていることを質問して、街までの短い距離で使われていた部分が抜き出されているので、回答候補にはありませんが、あながち間違いでもなさそうです
候補の選択
抽出された回答と候補をベクトル化し、cos類似度を比較します。
ベクトル化にはPart6のときに使用した関数を利用します。
# 文章ベクトルを取得する関数
def get_bert_vec(c):
tokens = tokenizer.tokenize(c)
ids = tokenizer.convert_tokens_to_ids(tokens)
ids = torch.tensor(ids).reshape(1,-1)
with torch.no_grad():
outputs, _ = model.bert(ids)
vec = outputs[0].numpy().mean(0)
return vec
answer_vec = get_bert_vec(ans)
c_vecs = [get_bert_vec(c) for c in candidate]
candidate1[cosine_similarity([answer_vec], c_vecs).argmax()]
# It was recently repaired.正解です!
抽出文とは離れていますが、他の選択肢が的外れすぎたのからでしょうか。
関数化
これまでの処理を関数化して質問2にも答えてみます
def part7_slover(text, question, candidate):
tokens = ["[CLS]"] + tokenizer.tokenize(question) + ["[SEP]"] + tokenizer.tokenize(text.replace("\n", " ")) + ["[SEP]"]
input_ids = tokenizer.convert_tokens_to_ids(tokens)
token_type_ids = [0 if i <= input_ids.index(102) else 1 for i in range(len(input_ids))]
with torch.no_grad():
start_scores, end_scores = model(torch.tensor([input_ids]), token_type_ids=torch.tensor([token_type_ids]))
all_tokens = tokenizer.convert_ids_to_tokens(input_ids)
answer_token = all_tokens[torch.argmax(start_scores):torch.argmax(end_scores)+1]
print("answer token:", " ".join(answer_token))
ans = ""
for a in answer_token:
if "#" in a:
ans += a.replace("#", "")
else:
ans += " "+a
print("extract answer:", ans)
answer_vec = get_bert_vec(ans)
c_vecs = [get_bert_vec(c) for c in candidate]
return candidate[cosine_similarity([answer_vec], c_vecs).argmax()]
part7_slover(text, question2, candidate2)
#answer token: Own ##er going overseas
#extract answer: Owner going overseas
#'She finds it difficult to maintain.'Ghorbaniさんが車を売る理由として、海外に行くことを抽出できているので、回答抽出はうまくいってそうですが、候補はうまく選べていません
異なる問題を解いてみる
もう一問解いてみました
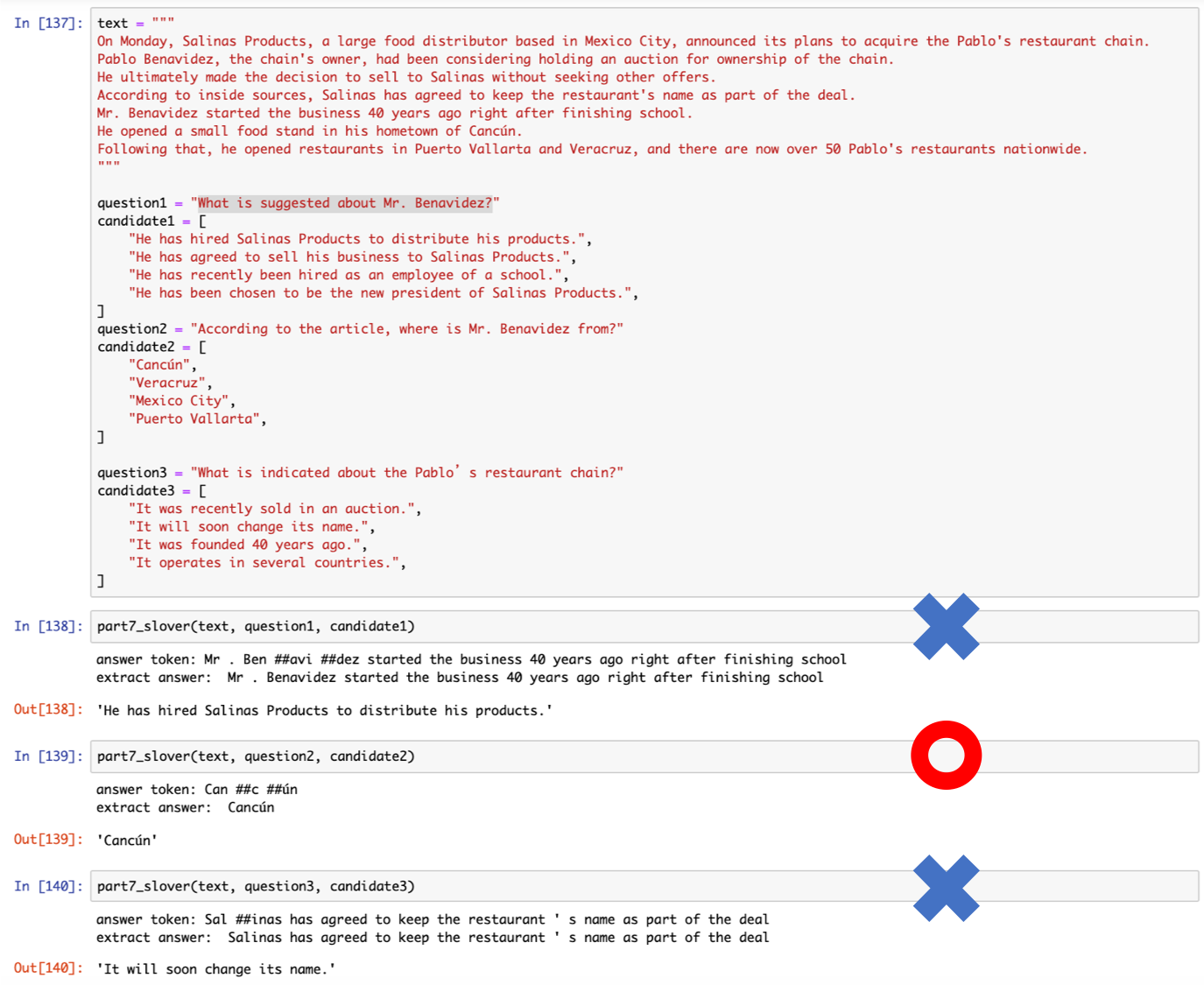
結果3問中1問正解と、あまりいい結果ではありませんでした。
質問1ははじめに解いた問題と同様「What is sugessted about 〜」で聞かれている質問で、抽出された回答はたしかに述べられている内容なのですが、候補と合っておらず間違った候補を選択してしまっています。
問題1ではたまたま正解でしたが、こういった類の問題が苦手なのかもしれません。
おわりに
本記事ではSQuADでfine-tuningされたBERTのモデルを使って、TOEICのPart 7を解いてみました。
総合成績は5問中2問正解であまり良くなく、以下のような弱点があるのではと考えました。
- 「What is sugessted about 〜」のようにテキスト中に複数回答部分が存在する問題
- 候補選択でのcos類似度による比較
そもそも(似ているとはいえ)違うタスクで学習したモデルを使っているので、この辺が限界かな、と思います。
3週連続で連載させていただいたBERTでTOEICの問題を解いてみるシリーズ、なんとかPart7まで来ることができました。問題を解く過程でtransformersの使い方など色々勉強できたので非常に楽しかったです。
最後まで読んでいただきありがとうございました




