こんにちは、AIチームの杉山です。
本日は、ACL2019のデモセッションで発表されたAlpacaTag: An Active Learning-based Crowd Annotation Framework for Sequence Taggingについて紹介します。
モチベーション
これまで、固有表現抽出を用いて個人情報のマスキングの検証を行ってきました。1 2
自動化のための要素技術に関しては調査や検証を行う中である程度の目処が立ってきたため、適用先として実際にマスキングを行うシーンを考えてみます。
自動化の仕組みがない場合、人手によるマスキングは以下のような流れで行うと思います。(我々が実際にグループ企業にマスキングを委託し実施した際の経験を元にしています。他に知見をお持ちの方、ぜひご教授ください。)
- 依頼者がデータを確認し、どんな種類の個人情報が含まれる可能性があるかを検討する
- 個人情報の保護に関する法律についてのガイドラインを参考に設計しました。
- 依頼者がマスキング対象のエンティティとルールを決める
- マスキングを行う際には、ただ該当箇所を黒塗りのような形で同一のタグに置換するのではなく、後段のタスクで使用する際になるべく情報を残したいため[電話番号]や[住所]のように種類ごとのタグを割り当てる必要があります。
- 依頼者がマスキング結果の査収(合格)基準を決める
- 作業者間の揺らぎや、疲れや操作ミスによる誤りが起こる可能性があるため、事前に査収基準を定めておくことをおすすめします。
- 作業者は何らかのツール(エディタ)でデータを開き、ルールに従いマスキングを行う
- 当時はcsvファイルを渡してエクセルなどで開いてもらい、テキスト中の個人情報を範囲選択->該当するタグに置換する、というなんともナイーブな方法で実施してもらいました。Clipyなどのツールで置換タグを複数登録しておくと多少作業は捗ります。
- 依頼者は結果を確認し、査収基準を満たしているかチェックする
上述した通り、当時は機械学習モデルを使った自動マスキングは行わず(正規表現で抜き出せる電話番号などは機械的に実施)、作業も決して効率が良いとは言えない環境で実施していました。しかし、マスキングにかかる時間やコストを考えると、より効率的で作業しやすい環境が必要であると考え調査をしていました。
個人情報のマスキングはいわゆる系列ラベリングのアノテーションに該当します。そのためのツールはすでにいくつか存在しておりEMNLPやCOLINGで報告されています。3 4
しかし、私が欲しい以下のようなツールは見つかりませんでした。
- doccanoのような直感的なインタフェースで、
- 範囲選択した箇所をいい感じのショートカットキーで素早くラベリングできて、
- その結果が一目で確認できて、
- 欲を言えば裏で固有表現抽出のモデルが動いていて事前にマスキングの候補がレコメンドされていて、
- 作業者は修正するだけでよく、
- さらにその作業履歴を適宜モデルの再学習に使用して随時モデルの精度が向上し、
- もっと言えば複数作業者の結果の揺らぎを吸収して欲しい
こういったツールがあれば便利だな、作りたいなと思っていたところ、これらを包括する機能を持つツールの論文が出ていると紹介していただき、読んだところWhat I wantで悔し素晴らしかったので、紹介させていただきます。
なお、紹介するAlpacaTagはアノテーションのためのツールです。系列ラベリングのために必要な量の学習データを作ることができれば十分なアノテーションと、基本的に全件に対して行う必要があるマスキングでは微妙に噛み合わない点もありますがご了承ください。
また、以降のまとめは落合先生フォーマットで行います。
どんなもの?
端的に言えば、論文タイトルのAlpacaTagは上述のニーズを満たすWebベースのアノテーションツールです。doccanoをベースに作成されており、最近の固有表現抽出でよく使われているBiLSTM-CRFのモデルがバックエンドで動作して自動でアノテーション対象のエンティティへのレコメンドを行います。Webベースなので複数人での作業結果を適宜統合することができ、Active Learningでアノテーションすべき文章順に作業を行うことができます。また、アノテーション結果を元に固有表現抽出のモデルを学習し、リアルタイムにモデルのデプロイを行うことが可能で、作業するほどモデルの精度が向上する仕組みになっています。
先行研究と比べてどこがすごい?
既存のOSSツールは主にデータ管理、ショートカットキーによる高速タグ付け、マルチプラットフォーム対応などのUIの利便性の向上に焦点を当てているが、本ツールでは特に以下の3点で新規性が主張されています。
1. active intelligent recommendation
バックエンドの固有表現抽出モデルを作業者のアノテーションに応じて段階的に学習することで、インスタンス(エンティティ)レベルとコーパス(文)レベルの両方で作業者の労力を軽減します。
インスタンスレベルでは、ラベル付けされていない文中からアノテーション対象を予測しレコメンドします。また、頻繁に使われる名詞(句)と、既にアノテーションされたスパンの辞書とのマッチングも行います。レコメンド結果や作業履歴は随時画面上に反映されるため、作業者は視覚的に確認したり、簡単に訂正したりすることができます。
コーパスレベルでは、Active Learningアルゴリズムにより次のアノテーション対象になるインスタンスを選択します。これにより、作業者がアノテーションするべき最も情報量の多いインスタンスを選択することで、より費用対効果を高く作業することができます。
2. automatic crowd consolidation
アノテーションを行う際には、作業者によってそれぞれに異なる確信度や好み、バイアスがあるため作業者間での意見の相違が生じる可能性があります。このようなノイズの多いアノテーションデータを用いてモデルを学習することは非常に困難であることが示されています。
そこで、アノテーション中に複数作業者のラベルを統合することで作業者はリアルタイムでのコンセンサスを得ることができ、アノテーションの不一致を減少させることができると考えられます。
3. real-time model deployment
アノテーション実施中に最先端の固有表現抽出モデルを展開することができ、ユーザーはAPIを利用してタグ予測を必要とするシステムの開発を容易に行うことができます。
技術や手法のキモはどこ?
メイントピックは、大きく以下の3点になります。
Tagging Suggestions (Instance-level Recommendation)
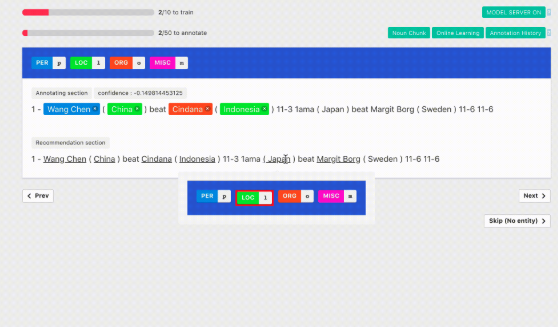
固有表現抽出モデルや辞書ベースのアルゴリズムによって予測された結果がどのように作業を支援するかを説明します。作業時には図のようなインタフェースが提供され、図2aのようにアノテーション対象と予測される箇所に下線が引かれます。予測結果があっていれば、作業者はドラッグして範囲を選択する必要はなく、そこをクリックするだけで十分です。
図2bではPERボタンに下線が引かれていますが、これは対象のエンティティのタイプのうち尤もらしいものを表しています。作業者は、各種ボタンをクリックもしくはショートカットキーを使って効率的にタギングすることができます。
作業後、図2cのように結果を確認できるため、操作ミスなどを視覚的に防ぐことができます。予測されていない箇所についても範囲選択することで任意のタグ付けを行うことができます。

Active Sampling(Corpus-level Recommendation)
作業者にどのインスタンスのラベル付けしてもらうかは、作業者の労力を省くために非常に重要です。ラベル付けされていない文全体の中から、最も情報量の多いインスタンスを選択するためにActive Learningを用います。情報量の指標はどのインスタンスが(正しくラベル付けされていれば)モデルの性能を向上させることができるかで決まります。Active Learningの典型的な例としては、Least Confidenceがあり、これはラベル付けされていないすべての文にモデルを適用し、推論信頼度を情報度の負の値として扱うものです。AlpacaTagでは、平均化によって配列の長さの影響を排除したMaximum Normalized Log-Probabilityという改良版を適用しています。これにより、ラベル付けされていない文の情報量を測定するために現在のモデルを利用することで、作業者がラベル付けするための最適な次のインスタンスを抽出できます。
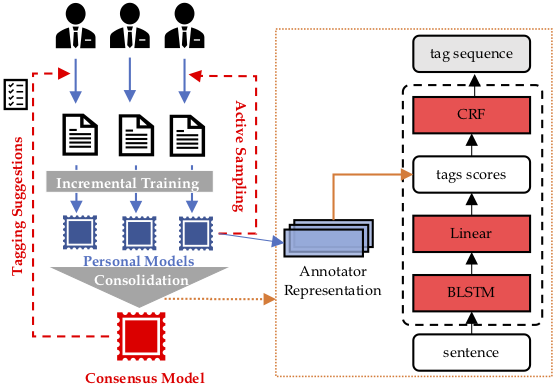
Automatic Crowd Consolidation
複数作業者で同時に作業する際、それぞれのモデルは作業者に合わせた形で更新します(Personal Model)。そこから作業者ごとの特性を表現する行列を獲得し、それを用いてConsensus Modelのtag scoresを再学習します。このように定期的に集約することで、作業者間の揺らぎを吸収し予測の精度を高めています。
どうやって有効だと検証した?
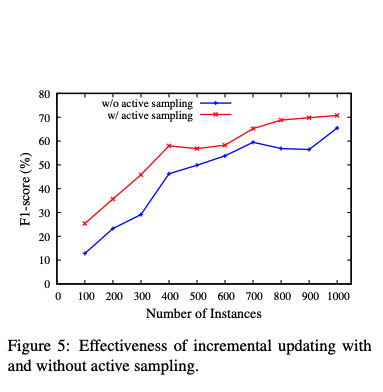
まず、Active Learningの有用性についてCoNLL2003の固有表現抽出の評価用データセットに対して、次の設定で実験を行ないました。100件のデータで学習を行いF1-scoreを評価し、また100件増やしてというサイクルを10回を行います。その際、追加する学習データをActive Learningで選ぶケースと、ランダムに選ぶケースで比較すると、以下の図のようにActive Learningで選択した方が常に良い精度となりました。またアクティブサンプリングを用いた場合、約35%の訓練データのアノテーションを用いるだけで、100%を用いた場合の性能を達成できることもわかったとのことでした。
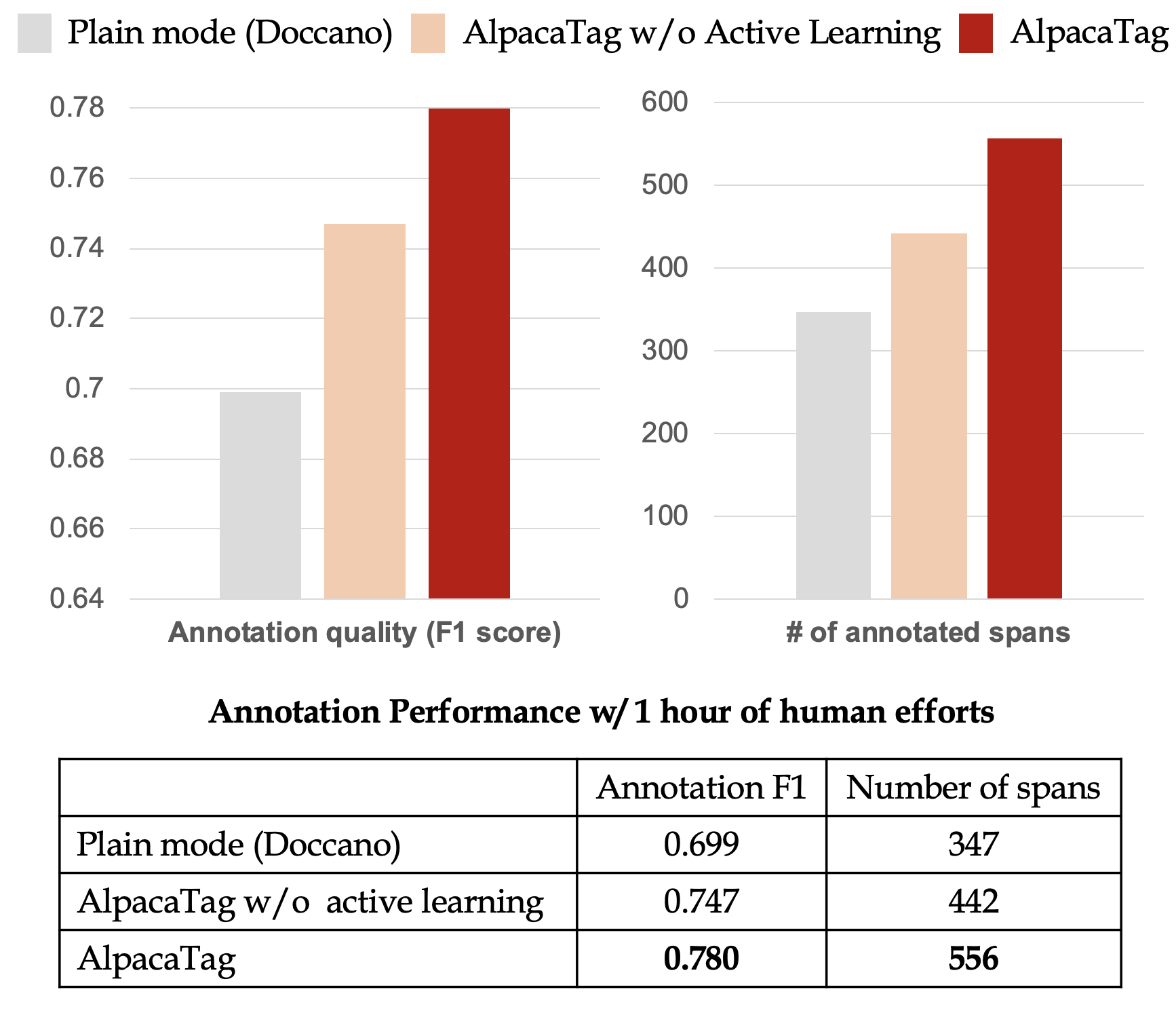
また、ツールとしての効率性を測定するためにAmazon Mechanical Turkを用いて外部作業者にアノテーションを依頼し、効率と精度の評価を行ないました。以下の図は1時間あたりのアノテーション数と精度を表しており、素のdoccanoを用いた場合とインタフェースはAlpacaTagだがActive Learningを用いない場合に比べ、提案手法がF1 score、アノテーション数で上回る結果となりました。
議論はある?
Future workでの議論やこの論文を引用している論文は見つからなかったのですが、現時点で私の思う効率的なアノテーションツールと合致しており、考える方向性として間違ってはいないのだな、と思いました。
次に読むべき論文は?
既存ツールとしてBRAT (Stenetorp et al., 2012)やWebAnno (Yimamam et al., 2013)、YEDDA(Yang et al., 2018a)が紹介されていましたが、どれも私のニーズを満たさなかったり本手法のサブセットになっているとのことでした。昨今のAIブーム(?)には学習データの効率的な作成が欠かせず、今後もどんどんツールが出てくると思うので引き続きウォッチしていきます。
終わりに
効率的なアノテーションツールであるAlpacaTagの論文について紹介してきました。読んでいて特にいいなと思った点は、エンティティの予測に固有表現抽出のモデルだけでなく頻出名詞句の辞書マッチなどルールベースライクな手法を組み合わせて予測の精度を高めている点です。以前の記事で述べたように、マスキングを効率的に行うためには、機械学習モデル、ルールベースの組み合わせの後段に人手を置いて、ヒューマン・イン・ザ・ループで取り組むのが現時点ではベストだと考えており、このツールはそれを体現していると感じました。
今後、固有表現抽出のアルゴリズムをこれまで私が試してよい性能だったFlairに置き換えたり、辞書ベースの箇所について事前に日本語の地名や苗字などの辞書を用意するなどすることでさらに精度の向上が見込めると思ったので、実用化に向けて引き続き試していきたいと思います。




