こんにちわ
AIチームの戸田です
先日、オンラインで開催された言語処理学会第26回年次大会でチャットボットの運用効率化手法についてのポスター発表をさせていただきました。
議論の中で、追加の比較手法としてLexRankを上げていただきましたので、今回はLexRankを実装して、追加実験をしてみようと思います。(発表内容につきましては報告記事をご参照ください)
LexRank
LexRankは、Webページの重要度をはかるPageRankに着想を得た抽出型の要約アルゴリズムで文書からグラフ構造を作り出して要約を行います。

PageRankとLexRankの考え方の比較を下記にまとめます。
| PageRank | LexRank | |
| グラフのノード | Webページ | 文章 |
| グラフのエッジ | リンク | 文章同士の類似度 |
| ノードの重要度1 | 多くのページからリンクされているページは重要なページ | 多くの文と類似する文は重要な文 |
| ノードの重要度2 | 重要なページからリンクされているページは重要なページ | 重要な文と類似する文は重要な文 |
実装
早速実装していこうと思います。
例文として、論文でも使用した問い合わせ群を使用します。
texts = [
"支払い方法変更",
"別の支払い方法を希望",
"支払い方法変更お願いいたします",
"デビッドカード支払いはできないのでしょうか 別の支払い方方法はないのでしょうか?",
"クレジットカードでの支払いでしたが、フィッシング詐欺にあってクレジットカードを停止しました。支払い方法を変更してコンビニ支払いにしたいので支払い方法をお知らせください。",
"お世話になっております。次回の[製品名]のお支払い方法をクレジットカードにしたいのですが、[不満内容]その先がわかりません。お返事お願いします。[氏名]",
]こちらの6つの問い合わせを簡潔に表している文章を代表文として抽出することが目的です。
特徴量は元論文でも使用されていたTF-IDFを使用したいので、形態素解析を行い、単語分割をします。
from pyknp import Jumanpp
jm = Jumanpp()
def wakati_jm(text):
result = jm.analysis(text)
tokenized_text =[mrph.midasi for mrph in result.mrph_list()]
return " ".join(tokenized_text)
corpus = [wakati_jm(t) for t in texts]
corpus[0] # '支払い 方法 変更'Juman++を利用した単語分割関数を作り、問い合わせ群をそれぞれ分割しました。
続いてTF-IDFを計算します。
TF-IDFの計算にはscikit-learnのTfidfVectorizerを使います。
model = TfidfVectorizer()
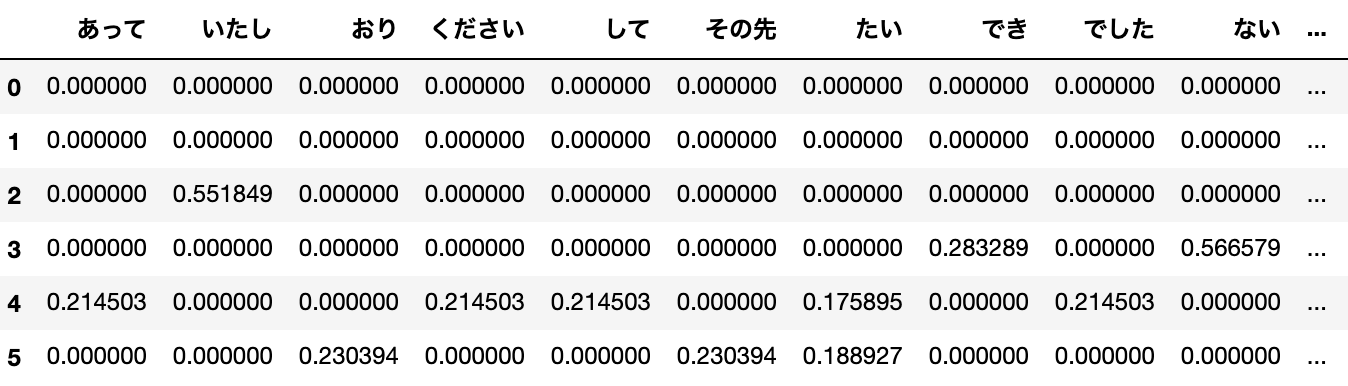
tfidf_vecs = model.fit_transform(corpus).toarray()計算されたTF-IDFをpandasを使って可視化すると以下のようになります。
次に文章同士の類似度を計算します。cos類似度で測ります。
cos_sim = cosine_similarity(tfidf_vecs, tfidf_vecs)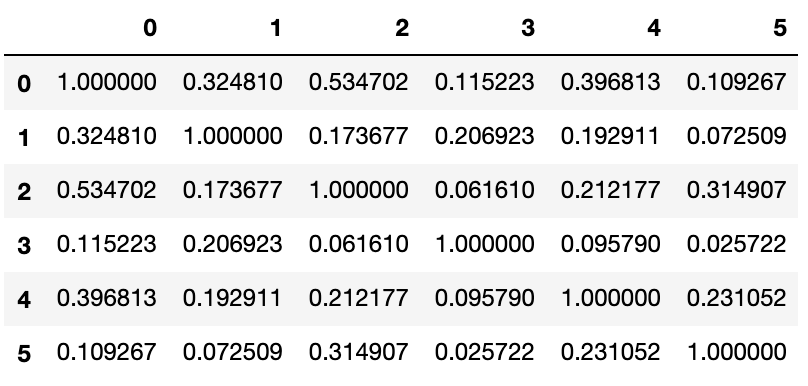
グラフとして扱うために、このcos類似度の行列を隣接行列に変換します。
cos類似度がしきい値(コード中thr)より大きければ1、そうでなければ0となります。しきい値はとりあえず0.5を設定してみました。
thr = 0.5
adjacency_matrix = np.zeros(cos_sim.shape)
for i in range(len(texts)):
for j in range(len(texts)):
if cos_sim[i, j] > thr:
adjacency_matrix[i, j] = 1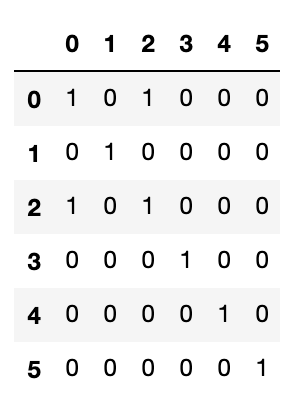
この隣接行列を確率行列に変換します。
stochastic_matrix = adjacency_matrix
for i in range(len(texts)):
degree = stochastic_matrix[i, ].sum()
if degree > 0:
stochastic_matrix[i, ] /= degree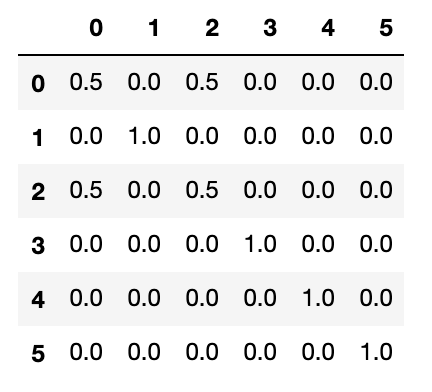
この確率行列からべき乗法をもちいて抽出した固有ベクトルがLexRankのスコアとなります。
べき乗法のpython実装は元論文のAlgorithm 2とこちらの記事参考にさせていただきました。
def power_method(stochastic_matrix, epsilon):
n = stochastic_matrix.shape[0]
p = np.ones(n)/n
delta = 1
while delta > epsilon:
_p = np.dot(stochastic_matrix.T, p)
delta = np.linalg.norm(_p - p)
p = _p
return p
lexrank_score = power_method(stochastic_matrix, 10e-6)元の問い合わせと比較した結果は以下になります。

あまり良くないです。
論文中では隣接行列を作る際のしきい値を調整していたので、thrを0.3に設定して再度実行してみます。

今度は良さそうです!
一番簡潔に答えられている「支払い方法変更」のスコアが一番高くなっています。
評価
私達の発表で使用した評価データを使って、他の手法と比較してみようと思います。
評価データ
EC、ゲーム、手続きの3つのドメインのデータで、手動で代表文をアノテーションしたものになります。
比較手法
LexRankはしきい値によって精度が変わってしまいそうなので、0.1, 0.3, 0.5の3つのしきい値を使用します。こちらを発表で使用した下記3手法と比較します。
- TF-IDF max: TF-IDFの最大値
- EmbedRank: BERTベクトルの重心とのcos類似度
- 提案手法: TF-IDFの最大値に低頻度語のペナルティを加える
評価結果
LexRankの評価結果は以下のようになりました。
| ドメイン | 評価指標 | しきい値0.1 | しきい値0.3 | しきい値0.5 |
| EC | MRR | 0.4305 | 0.4884 | 0.1319 |
| EC | MAP | 0.3815 | 0.4511 | 0.1260 |
| ゲーム | MRR | 0.1026 | 0.0444 | 0.0478 |
| ゲーム | MAP | 0.1111 | 0.0425 | 0.0556 |
| 社内手続き | MRR | 0.2456 | 0.1513 | 0.0526 |
| 社内手続き | MAP | 0.2456 | 0.1390 | 0.0526 |
発表での手法の評価結果は以下のようになります。
| ドメイン | 評価指標 | TF-IDF max | EmbedRank | 提案手法 |
| EC | MRR | 0.9236 | 0.8356 | 0.9236 |
| EC | MAP | 0.9064 | 0.7657 | 0.9141 |
| ゲーム | MRR | 0.8148 | 0.7359 | 0.8259 |
| ゲーム | MAP | 0.8100 | 0.7079 | 0.8225 |
| 社内手続き | MRR | 0.7149 | 0.7215 | 0.8026 |
| 社内手続き | MAP | 0.7202 | 0.7231 | 0.8035 |
全体的にLexRankの結果はあまり良くなさそうです。
考察
LexRankの結果が振るわなかった理由として、しきい値などの要素もありそうですが、もともとLexRankは新聞記事のような長文を要約することを目的とした手法なので、今回の対象文章(4〜6文章)だと少なすぎたのかもしれません。
文書特徴にBERTなどを利用する方法も考えられますが、今回はここまでとしたいと思います。
おわりに
今回はLexRankを使って、言語処理学会で発表した評価実験の追加実験をおこなってみました。結果、素のLexRankではあまり良い結果を得ることができませんでしたが、逆に言えば提案手法の優位性は変わらなかったと捉えることも出来ると思います。
LexRankは今回始めて触りましたが、かんたんに実装できて係り受け解析もせず要約できるのはなかなかおもしろい手法だと思いました。
最後までお読みいただきありがとうございました。




